21. High Availability¶
This section describes how to deploy several instances of RDFox to work together to provide a service with high availability.
Availability is the non-functional characterstic of a system that determines what proportion of the time the system is available for its intended use. Achieving high availability (HA) for a software service in the face of unpredictable problems such as power failures, network outages, and fires, requires running multiple copies of the service with identical or close to identical data so that if one fails, there are still other instances to service inbound requests.
Making several service copies with identical data (also known as replicas) is
trivial for read-only services but more challenging for services that allow
data to be modified as well as queried. The latter case requires a mechanism to
ensure that new changes committed via one replica, are propagated to the
others. In RDFox, this is achieved by configuring the instances to use the same
server directory, and then load-balancing the inbound requests over those
instances. In order to share a server directory, RDFox instances must be
configured to use the file-sequence persistence type described in
Section 13.2.2.
The characterstics of RDFox HA deployments are described in the following section. It is important that both developers and operators understand these aspects of RDFox HA deployments. Section 21.2 describes the general workflow for creating new RDFox HA deployments while Section 21.3 sketches some possible load balancing approaches.
21.1. Characteristics¶
RDFox HA deployments have the following characteristics.
- Leaderless
All the instances that share a server directory are equivalent: there is no leader or master role. This means that any instance will accept writes without needing to communicate with other instances. This supports a range of different load balancing strategies, some of which are reviewed in Section 21.3.
- Dynamic
Additional replicas can be added at any time just by launching them with the appropriate parameters. New instances become available as soon as they have loaded the existing data from the server directory.
- Eventually Consistent
Each change becomes visible on the non-committing instances at some point after the change is successfully committed. In most cases it is useful for changes to be replicated as soon as possible after commit. For a discussion of how to achieve the lowest possible replication lag, please refer to Section 13.2.2.2.
Eventual consistency is a widely-used consistency model but correct usage requires developers to understand the implications. These issues are explored briefly in Section 21.3.
21.2. Recommended Deployment Steps¶
This section describes, at a high level, the recommended steps for provisioning a new RDFox HA service.
Provision a file system to contain the server directory for the deployment. The file system must meet the requirements specified in Section 13.2.2.1 and must have sufficient capacity for the data that will be loaded into RDFox.
Provision a separate host for each of the desired number of RDFox instances. Each must have sufficient memory to store the data that will be imported and at least one CPU core for each desired RDFox thread.
Download and unzip the RDFox software archive onto each host.
Make sure that a valid, in-date license key is accessible from each host. See Section 2.4.1.3 for the full list of ways this can be provided.
If desired, create a directory on the file system that will act as the shared server directory. Otherwise, the root of the file system can be used directly for this purpose.
Mount the server directory to each of the hosts. In the following steps,
<host-server-dir>will represent the path at which the server directory will be found on a given host.Using one of the hosts, add a server parameters file at path
<host-server-dir>/parameterswith at least the following lines:persist-roles file-sequence persist-ds file-sequence
On one of the hosts, launch RDFox in
shell modeto initialize the server directory for access control, as described in Section 12.3.1. The command line must explicitly set theserver-directoryserver parameter to<host-server-dir>. Please refer to Section 18 for details of the command line arguments supported by RDFox. Once access control has been initialized, close the process down with thequitcommand.Determine the network name for each host and choose a UDP port number at which the host will receive notifications about new versions from other instances. We will use
<hostname>and<port>to represent these values in what follows. Ensure that UDP packets can be sent from the other hosts to the chosen hostname and port number.On each of the hosts, launch RDFox in
daemonmode to start the RDFox endpoint. Again, the command line must explicitly set theserver-directoryserver parameter to<host-server-dir>but this time thenotifications-addressserver parameter should also be set using the hostname and port determined above. It is usually also desirable to enable request logging. The launch command may be built using the following template:RDFox -server-directory <host-server-dir> -notifications-address <hostname>+<port> daemon request-logger elf
Please refer to Section 18 for details of the command line arguments supported by RDFox.
Finally, establish load balancing over the instances using external software. The following section outlines some possible approaches.
21.3. Suggested Approaches to Load Balancing¶
The following section describes a selection of load balancing topologies that can be used with RDFox HA to help illustrate the relevant considerations. Whichever approach is chosen, it is crucial that developers working with the system understand what guarantees they can expect from the service or services.
The following sections make some assumptions about the infrastructure used for the RDFox HA deployment. First, it is assumed that, where a group of instances is used, there is some system responsible for ensuring that the group contains the desired number of healthy instances at all times, with the capability to start new instances when this is not the case. This could be done manually but will most often be autonomous. Second, it is assumed that the load balancer can be configured to route traffic to the healthy instances within such groups. Kubernetes is an example of a system that meets these criteria.
21.3.1. Single read-write Service with Single Group of Instances¶
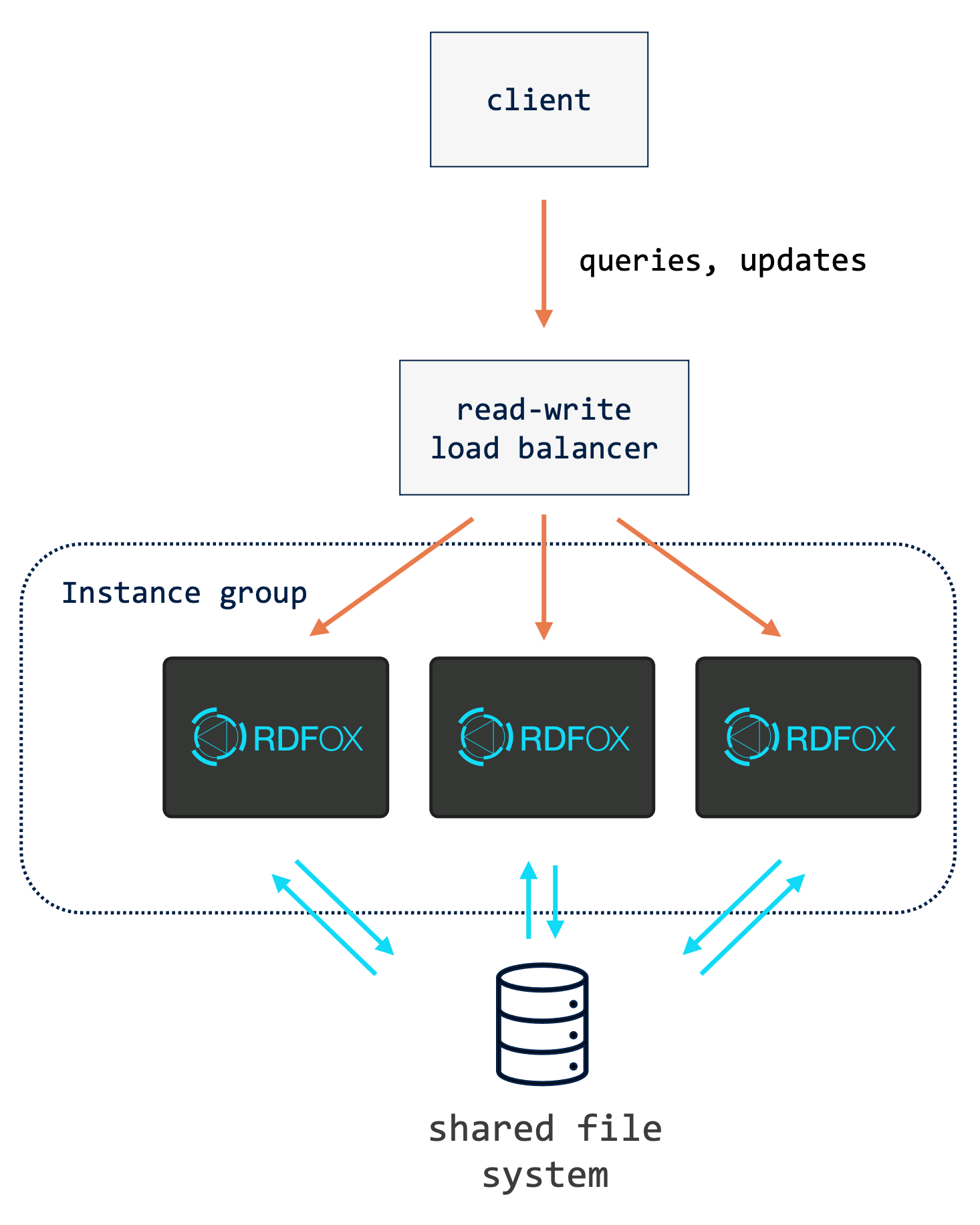
For deployments with infrequent updates, the simple load balancing topology depicted above is a good choice. This uses a single load balancer to distribute all types of request over all of the instances that share the server directory. As well as being easy to configure, this gives developers a single service identity for use in code, regardless of whether they are performing a query or update, and gives the same availability for both of these types of traffic.
One downside to this approach is inefficient handling of write contention. The problem can be explained as follows. Imagine that all of the replicas in the group are in sync at version v of the data store when two clients attempt to apply changes concurrently. These changes could be to add or remove data via import or to apply arbitrary SPARQL udpates. Imagine also that the two requests are routed to different replicas. In this situation, each replica starts a read-write transaction, applies the modification specified in the request to its in-memory state, and attempts to commit the change by writing it to the path for version v+1. Only one commit will succeed. The unsuccessful replica will then have to roll back the changes to its in-memory data and then report the error to the client which will then have to retry at the cost of at least one more server round-trip.
Next, imagine that both requests are instead routed to the same replica. This time the RDFox instance will, as before, begin a read-write transaction for the first request that arrives. The thread servicing the second request will, however, see that the data store is locked and wait for up to two seconds to start its own transaction. If the first request completes within this time, the transaction for the second can begin immediately and the change specified by that request will also be applied. In this version of events, neither client experiences an error and the throughput is higher.
With a single read-write service balanced over all of the replicas, there is no way to ensure that all write traffic goes to the same replica, so the inefficient write contention situation remains possible. If concurrent writes are expected to occur frequently, one of the topologies described in the following sections may give better results.
As well as the write contention issue, this load balancing topology fails to automatically provide read-your-own-writes consistency. This can be important when a user makes a change via some user interface and expects the effects of that change to be visible immediately afterwards. If the request that makes the change is routed to one instance, but a subsequent follow-up query to refresh the UI is routed to another instance that has not yet replicated the change, the query will return stale results.
There are two ways to address this problem without changing to a different load balancing topology. The first is for the client to save the ETag returned in the HTTP response for the update request and then to repeat the query request until a matching or higher data store version number is returned (see Section 16.14.1). The other is to choose a load balancer that supports “sticky” sessions. Sticky sessions are a mechanism to improve the likelihood that successive requests from the same client are routed to the same instance.
21.3.2. Separate read-only and read-write Services with Dedicated Writer Instance¶
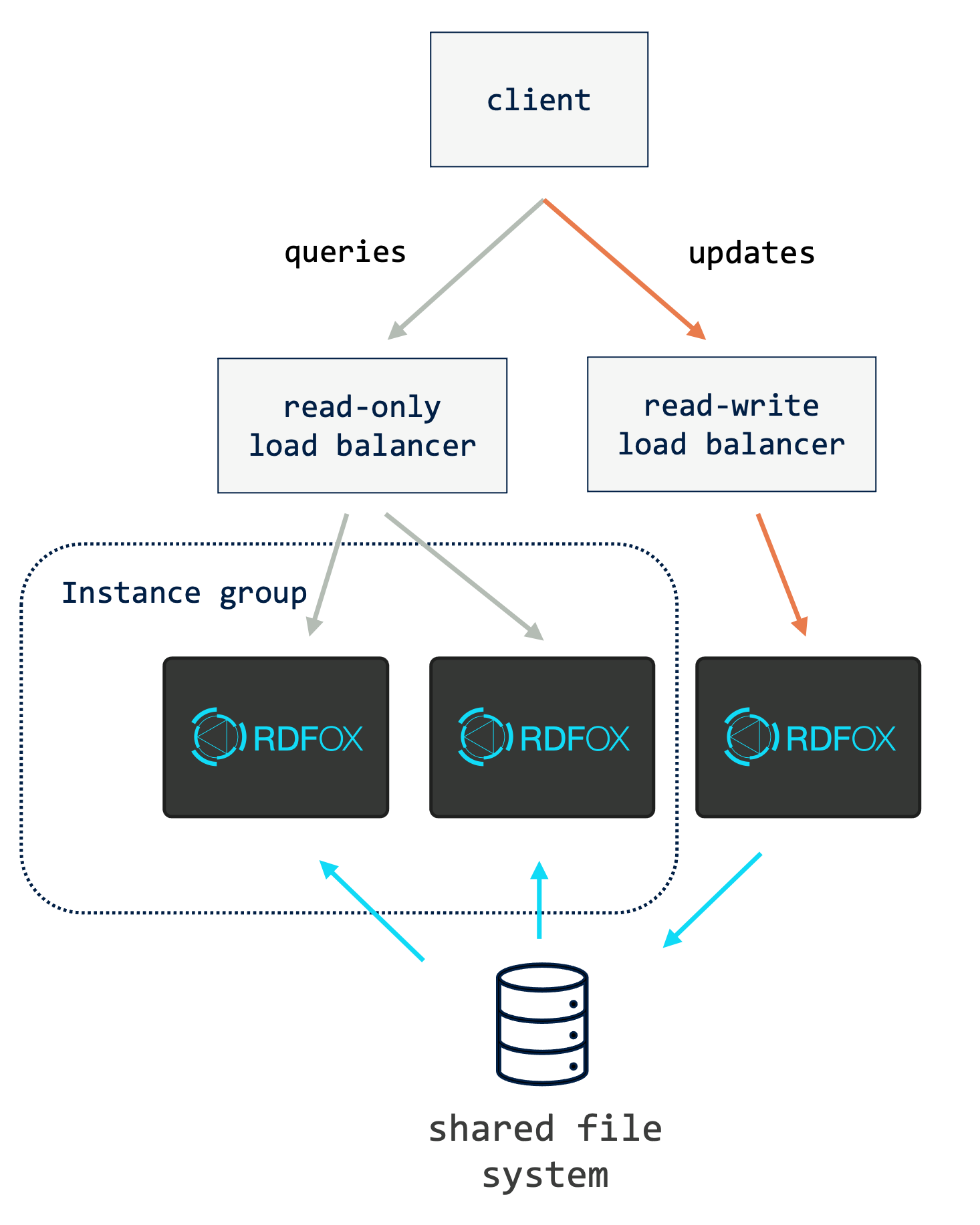
For deployments which need to support frequent updates, especially where these might be concurrent, it is useful to distinguish read-write requests (updates) from read-only requests (queries) and to use a dedicated instance to process the read-write requests as depicted above. This brings the advantage that updates do not have to contend with queries (see Section 11.3).
For this scheme to work, application code must be aware of the two service identities and call the right one in each case otherwise the advantage of the dedicated writer is lost. If read-your-own-writes consistency is needed to support particular user interactions, developers may use the ETag solution described in the previous section, or may choose to send the follow-up query to the read-write service. This does reintroduce the risk that updates may have to contend with queries however this may be acceptable if the user interaction is rare.
A potential disadvantage of this topology is lower availability for read-write traffic. In the first topology we looked at, availability was the same for both types of traffic: a single instance becoming unhealthy would still leave n-1 instances available to service any request. In the current topology, a failure of the dedicated writer instance means that, while read-only requests can still be served, the service is unavailable for writes until the writer recovers or is replaced. In the case where it must be replaced, the outage will last at least as long as it takes to start the new instance and for it to restore the persisted data.
This topology is also well suited to situations where queries and updates arrive from different groups of clients. For example, a read-only query service provided to a group of users that is regularly refreshed from the output of an extract-transform-load (ETL) pipeline. In this case, only the pipeline would need access to the read-write load balancer.
21.3.3. Separate read-only and read-write Services with Single Group of Instances¶
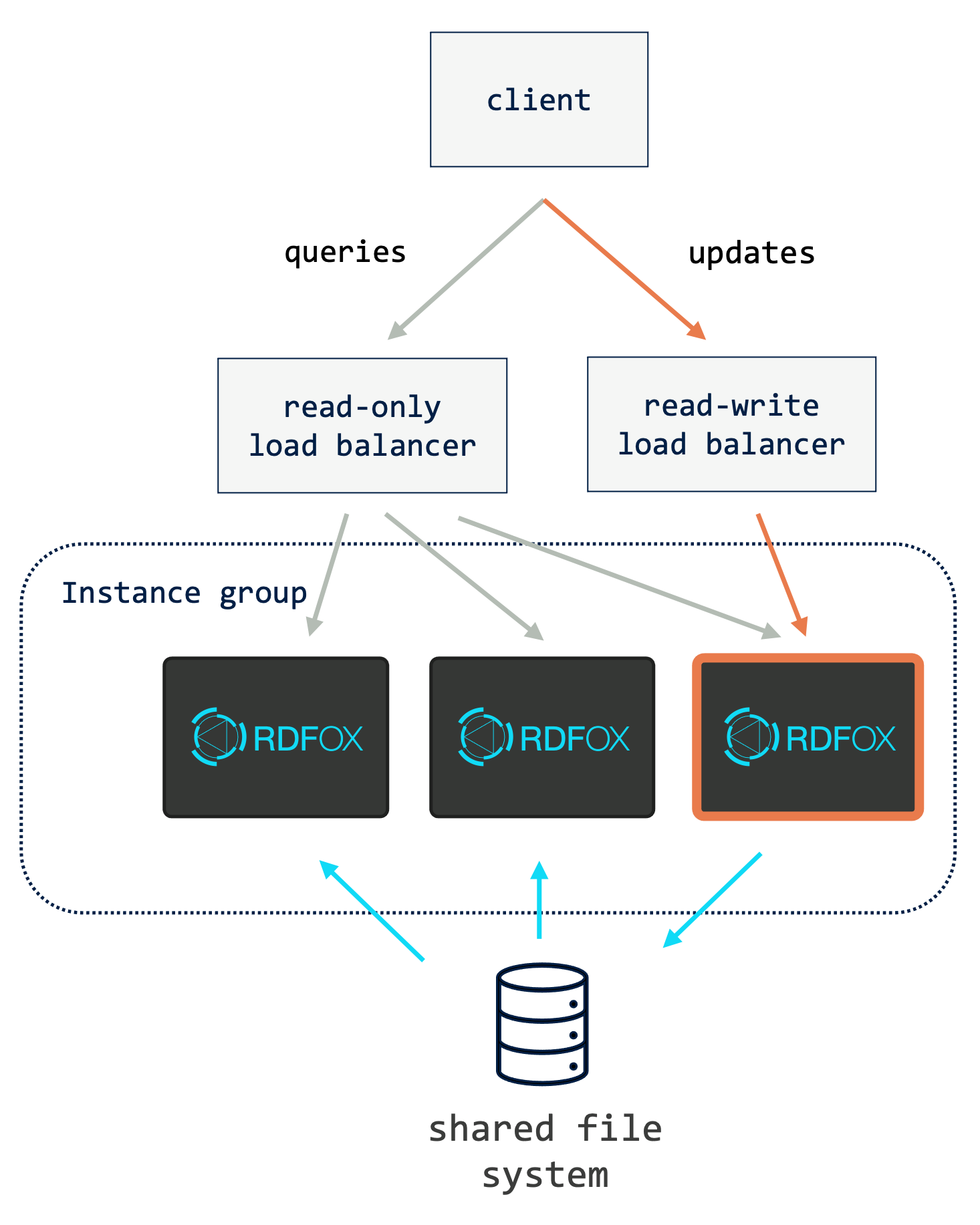
If an application requires better write throughput than the first topology but with faster recovery from writer failures than with the second topology, read-write requests can be forwarded to one of the instances from the main group instead of to a dedicated writer. This is depicted in the image above. The selected instance will receive all of the read-write requests plus a share of the read-only requests.
As with the previous topology, this arrangement guarantees that all writes are performed by the same RDFox instance. Here, however, recovery from writer failures should be faster because the writer responsibility can be simply reassigned to another running instance rather than having to wait for a new instance to start (this is known as failover). Again, read-your-own-writes consistency can be achieved with ETags or by using the read-write service for both the update and follow-up query.
Disadvantages of this setup include the fact that the total workload is not evenly distributed and that writes have to contend with queries. There is also additional complexity associated with the need to ensure that the read-write load balancer knows which one of the running instances it should route requests to at any given moment. This could be done manually but if the selected instance becomes permanently unavailable, manual intervention will then be needed to restore read-write service.
To assign this responsibility automatically, with automatic failover, a standard leader election layer can be added. Although this seems at odds with the description of RDFox HA as “leaderless”, there is no contradiction since the RDFox instances remain equivalent. This means that there is no risk of a problem known as “split brain” where more than one instance thinks that it is the leader. In RDFox HA, if the read-write load balancer is temporarily configured to route requests to more than one of the instances, no data loss or error will occur; the system will gracefully degragde to a situation similar to the first topology described above.